Favyen Bastani, Sam Madden. SIGMOD 2022.
Links: [PDF] [Code] [Dataset] [Talk]
Summary: Recent work in video query optimization has focused on building systems (e.g., Miris, BlazeIt, TASTI) that employ query-specific processing, such as training and applying per-query proxy models, to minimize query execution cost. These systems generally focus on optimizing object position or track queries that reason about the objects that appear in the video, e.g., find frames containing at least three buses.
However, video query optimizers are difficult to deploy in practice because they require queries to be re-developed in an entirely new framework. Additionally, specialized per-query processing means that limited work can be shared across queries, making these systems slow for executing many queries over the same video dataset.
In OTIF, we explore the alternative approach of tuning machine learning pipelines to efficiently compute object detection and tracking outputs that generalize across many queries. We find that, by jointly tuning object detection and tracking components, we can extract the positions and tracks of all objects in a video as fast as state-of-the-art video query optimizers can answer a single object position or track query. Once tracks are computed, several such queries can be answered in less than a second; indeed, when executing five queries on the same video dataset, OTIF is 23x faster than Miris, 6x faster than BlazeIt, and 9x faster than TASTI. Furthermore, OTIF avoids the development complexity associated with video query optimizers: users can first extract tracks with OTIF, and then reuse their existing infrastructure to answer queries about those tracks.
Abstract: Performing analytics tasks over large-scale video datasets is increasingly common in a wide range of applications, from traffic planning to sports analytics. These tasks generally involve object detection and tracking operations that require pre-processing the video through expensive machine learning models. To address this cost, several video query optimizers have recently been proposed. Broadly, these methods trade large reductions in pre-processing cost for increases in query execution cost: during query execution, they apply query-specific machine learning operations over portions of the video dataset. Although video query optimizers reduce the overall cost of executing a single query over large video datasets compared to naive object tracking methods, executing several queries over the same video remains cost-prohibitive; moreover, the high per-query latency makes these systems unsuitable for exploratory analytics where fast response times are crucial.
In this paper, we present OTIF, a video pre-processor that efficiently extracts all object tracks from large-scale video datasets. By integrating several optimizations under a joint parameter tuning framework, OTIF is able to extract all object tracks from video as fast as existing video query optimizers can execute just one single query. In contrast to the outputs of video query optimizers, OTIF's outputs are general-purpose object tracks that can be used to execute many queries with sub-second latencies. We compare OTIF against three recent video query optimizers, as well as several general-purpose object detection and tracking techniques, and find that, across multiple datasets, OTIF provides a 6x to 25x average reduction in the overall cost to execute five queries over the same video.
Technical Overview:
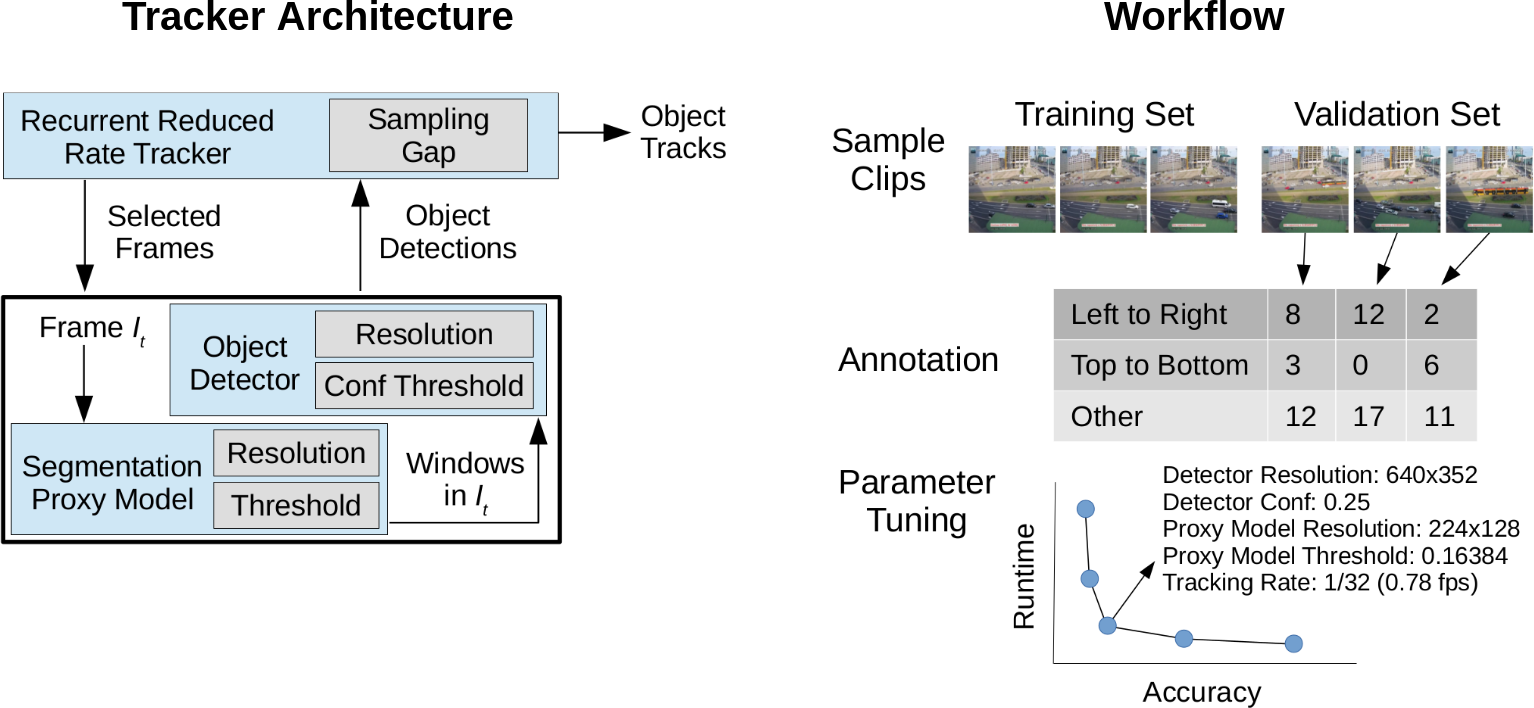
We develop an object detection and tracking architecture that exposes several (five) parameters that can be tuned to provide a good tradeoff between speed and accuracy for a given dataset. These parameters control different aspects of the three components of OTIF's execution pipeline: (1) in the object tracker, we control the rate of frames that we process; (2) in the object detector, we control the detector's input resolution and confidence threshold; and (3) in the segmentation proxy model, we control the proxy model's input resolution and confidence threshold. The segmentation proxy model is a fast model that inputs video at a very low resolution to minimize the number of pixels that have to be processed through the slower object detector (see the paper for details).
We then use a sampling-based approach to tune the parameters in the architecture for a particular video dataset. First, sixty one-minute clips of video are uniformly sampled to build each of the training and validation sets. Various models, including the object tracker and the segmentation proxy model, are trained on the training set. Then, we greedily update parameters starting from the slowest possible parameter configuration to obtain a speed-accuracy curve (hopefully close to the Pareto-optimal curve), where every point corresponds to one parameter configuration. Finally, we present this curve to the user, who can then pick parameters to use for processing the rest of the dataset.
In prior work, object detection and tracking are considered slow operations whose performance issues can only be mitigated for certain types of queries through query-specific video processing. In contrast, we find that Object Tracking Is Fast, and that leveraging a wide range of optimizations brings tracker performance close to video decoding speed. Our results suggest that current video query optimizers face significant challenges in competing with fast object trackers, and that further improving the speed-accuracy tradeoff of object tracking and other computer vision tasks is likely a more promising future direction.