Favyen Bastani, Songtao He, Sam Madden. NeurIPS 2021.
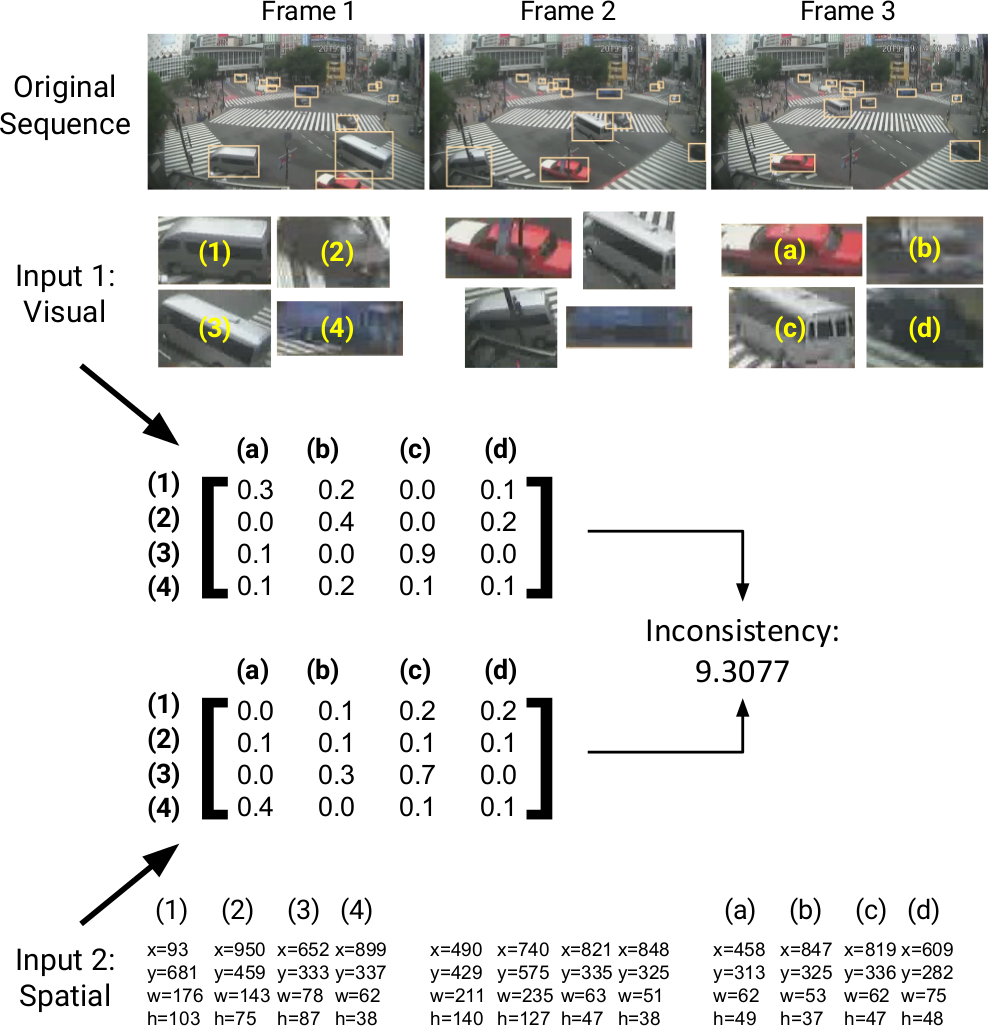
Abstract: In this paper, we propose a self-supervised learning procedure for training a robust multi-object tracking (MOT) model given only unlabeled video. While several self-supervisory learning signals have been proposed in prior work on single-object tracking, such as color propagation and cycle-consistency, these signals cannot be directly applied for training RNN models, which are needed to achieve accurate MOT: they yield degenerate models that, for instance, always match new detections to tracks with the closest initial detections. We propose a novel self-supervisory signal that we call cross-input consistency: we construct two distinct inputs for the same sequence of video, by hiding different information about the sequence in each input. We then compute tracks in that sequence by applying an RNN model independently on each input, and train the model to produce consistent tracks across the two inputs. We evaluate our unsupervised method on MOT17 and KITTI -- remarkably, we find that, despite training only on unlabeled video, our unsupervised approach outperforms four supervised methods published in the last 1--2 years, including Tracktor++, FAMNet, GSM, and mmMOT.